ライブラリや言語のバージョンを継続的に上げるという営みについて
ライブラリとか言語のバージョンを上げるの、自分の中では一般常識というか「なんでやらないの」くらいのもんだったんで、逆に「なんで上げるんですか」と尋ねられた時にパッと答えられなかった (脆弱性対策とかそういうのはすぐ言えるんだけど、なんというか「仕草」の話題だと思っており……
— moznion (@moznion) 2026年2月20日
ここ10年以上「バージョンを上げる」ということは習慣的にずっとやり続けていることであったので、いざ突然「なぜ?」と問われるとその場でパッと答えられないことに気付きました。瞬発力の無さが情けない……もちろんその効能についてはしっかり理解している (はずな) のですが、ちゃんと整理しておいたほうが良さそうということで言語化しておこうと思います。
個人の根源的な思いとしては、かつて上記の記事に書いた
最新バージョンの言語やライブラリ、追いたいですよね。バグが直っていたり、新しい機能が使えたり、パフォーマンスが改善されていたりと良いことづくめなことに加え、新しいバージョンを使っているとなんだか不思議と気分が良いものです。
というところに帰着するとは思いつつ、某所で ![]() id:masawada が整理してくれた
id:masawada が整理してくれた
- バージョンを上げ続けないと、どこかで上げるのに失敗した時に原因の切り分けが難しくなる
- 世の中一般のバージョンと乖離すると、世の中の知見をそのまま取り込めなくなる
- 素朴にバージョン上がってるほうが便利になっているはず
という内容が正鵠を射ているように感じています。
また ![]() id:stefafafan が指摘してくれた「(バージョンアップによる) エンバグ避けたいなら機能追加や改修もやめてメンテナンスモードにするしかない」という言葉も良いなと思っており、つまり成長させ続けなければならないサービスにおいては諸々のバージョンアップは避けられない (すべきである)、というところに落ち着くのであろうと思っています。
id:stefafafan が指摘してくれた「(バージョンアップによる) エンバグ避けたいなら機能追加や改修もやめてメンテナンスモードにするしかない」という言葉も良いなと思っており、つまり成長させ続けなければならないサービスにおいては諸々のバージョンアップは避けられない (すべきである)、というところに落ち着くのであろうと思っています。
あるいは ![]() id:tomo_ari が言っていた
id:tomo_ari が言っていた
osyoyu [22:59]
Rubyのバージョンを上げたいのは、自分にとってはRubyが圧倒的に "自分のもの" だからだと思う、自分や知人が作った最新の機能が入ってるバージョンは当然使いたいよねみたいな
osyoyu [23:00]
MySQLやAuroraやLinuxについても、それなりに知っていることである程度近しい感情はあって、上げない理由がないようなところがある
osyoyu [23:01]
なので、対象をよく知ると良い説がある
というのも良いですね。これは「知らないものに対して抱く恐怖」にまつわる話題と同等であるという認識をしており、よく知らないもののアップグレードは怖いのでやりたくなくなってしまうため、その悪循環を断ち切る為には対象に詳しくなるのが良い、というのはその通りであると思います。
その他いただいていたおたよりについてはこちら:
バージョン普段から上げておかないと、「まずgradle pluginのバージョンを1上げてからgradleのバージョンをあげてjavaのバージョンをあげてからgradleのバージョンをあげて。。」とかやらないと脆弱性対策パッチが当たらなくなったりするという都市伝説 https://t.co/4EVTL5iMjN
— 徳永広夢 (@tokuhirom) 2026年2月20日
塩漬けするやつは気にしないけど後からなんとかするやつが苦労する、というのを実感させるには5年ぐらい必要、という構造の問題なので(飲み会で話そう
— fujiwara (@fujiwara) 2026年2月20日
バージョン管理とは沼であり、一度沼にハマったら抜け出せず、世のベストプラクティスと乖離していき、生産性は落ち、離職率は上がり、ダサい会社と見なされ、現場は荒れ、人事は風評に悩み、社長はそれを知らない https://t.co/B0Ri1Knlj9
— mizchi (@mizchi) 2026年2月21日
ライブラリのアップデートを塩漬けにするといざ必要になった時にアップデートが死ぬほど面倒になっているという経験則からのやつなので経験しないとわからないものではあると思う。
— だし巻き卵 (@mashiro) 2026年2月21日
逆に捨てていいものならあげる必要もない。 https://t.co/ZDhzGmbW5f
放って置くと、これを上げるには先にあっちを上げて、バージョン揃えて…って作業が発生して、しまいには半端に古いバージョンで一旦足並みを揃えて、アプリ側コードも修正して、みたいになってくるので
— Sho Hashimoto (@shokai) 2026年2月21日
色々あるとは思いますが、頑張っていきたいですね。
[追記]
諸々まとめて
— P山 (@pyama86) 2026年2月21日
「最新が最高」
って大声で言うことで乗り切っている。 https://t.co/MAbUHQLFGP
実際には僕もそのようにやってはいて、それが冒頭のPostの文中で「仕草」と表現したものになるのですが、そのような荒技が可能なのは大半のメンバーの認識・意識が合っている場合に限る気はしており、そこをこう、上手くやりたいですよね。頑張りたいですね。
所属変更のお知らせ
2026年1月1日より、次の通り所属が変更されています *1。
前: 株式会社スマートバンク
現: タイムリープ株式会社
前職在職中は大変お世話になりました。ありがとうございました。
タイムリープ株式会社ではリモート接客プラットフォーム (サービス名: RURA) を中心としたプロダクト作りをやっています。小さなチームでプロダクト開発をするのはなんだかんだ久々な感じで良いですね。
製品については実際に既にお客様にもご利用いただいており、便利で良いものであるように思っています。提供しているものの中には実ハードウェアもあったりするのでそこが燃えるポイントでもあります。
自分はエンジニアなのでもちろんエンジニアリングを行うのですが、チーム作りのようなこともやっています。というかそっちの比重の方が今は高いまであり……という今までの自分のキャリアでやったことが無い状況になっています。
とにかくReactで書かれたフロントエンドアプリのスペシャリストを渇望しています。WebRTCを中心に据えたブラウザで動作する遠隔接客プラットフォームに少しでも興味・関心のある方、何卒ご連絡ください! 会話しましょう!!! ちなみにサーバーサイドはGoです。
以下、近況です:
最近やっていること: エンジニアリングマネジャー (なぜ)、型パズル (なぜ)
— moznion (@moznion) 2026年1月23日
これはガチの話で、Reactで作られた遠隔接客フロントエンドを一緒にゴリッゴリに良くしていく仲間を募集しており、サラリーもガツンと出しますんで、興味ある方ご一報ください、マジで!!!!! 腕に覚えのあるひと絶対来てくださいhttps://t.co/s4GXIvfWcG
— moznion (@moznion) 2026年1月23日
俺がちゃんと採用活動をやってるの、異常事態であることを理解してほしい
— moznion (@moznion) 2026年1月23日
*1:1ヶ月経ってから報告したほうが色々と安全であるという学びがあるため遅れての報告になりました
Bundler 4.0.0を実戦投入した
Bundler 4.0.0が出ましたね。めでたい。ということで早速4.0.0にアップグレードしてみました。
オフィシャルの情報としての4.0.0の差分およびアップグレードガイドは ^ を見ると良いです。
実際にやったこと
bundle up --bundler=4.0.0を実行してlockファイルを更新bundle installの後にbundle binstubs bootsnapをするように追加 *1- bootsnapだけでは足りず、ridgepole等も含める必要があることに気付いたため上記を
bundle binstubs --allを使うように変更 bundle lock --add-checksumsを実行してlockファイルにCHECKSUMSを追加
binstubsの処遇は若干難しく、アップグレードガイドには
The --binstubs flag would create binstubs for all executables present inside the gems in the project. This was hardly useful since most users only use a subset of all the binstubs available to them. Also, it would force the introduction of a bunch of most likely unused files into source control. Because of this, binstubs now must be created and checked into version control individually.
とあるため、使うexecutableに絞ってbundle binstubsを実行してスリムに保ってね、というモチベーションであるということは理解しつつも、既存の系に対して適用しようとすると「どのexecutableが必要なのか」がパッと自明にわからず、一旦は安全側に倒して--allを使って全生成することとしています。
これについては同僚の![]() id:ohbaryeさんがruby-jpのSlackチャネルで質問してくれている *2 ので、今後何か進展があるかもしれません。
id:ohbaryeさんがruby-jpのSlackチャネルで質問してくれている *2 ので、今後何か進展があるかもしれません。

[追記]
> it would force the introduction of a bunch of most likely unused files into source control.
とあるように、生成されたexecutablesがバージョン管理の対象になって複雑性が増すことが懸念なのであれば、今回のような用途、つまりコンテナのビルドステップ内でbundle binstubs --allを実行するのはそのコンテナ内に生成物が閉じるので大きな問題ではないように思いました。
そもそもbundle installで依存ライブラリ自体はインストールされているので、binstubsでexecutableを生成しようがしまいがコンテナサイズにも大きな影響はなさそうです。
![]() id:h-sbtさんからも「とりあえず最初の一歩としては
id:h-sbtさんからも「とりあえず最初の一歩としては--allを使うので良いのではないか」というアドバイスもいただきました。
[追記ここまで]
lockファイルにCHECKSUMSが追加される挙動がデフォルトになったとのことだったのでこちらも導入しました。
We shipped this security feature and turned it on by default, so that everyone benefits from the extra security assurances. So whenever you create a new lockfile, Bundler now includes a CHECKSUMS section.
Bundler will not automatically add a CHECKSUMS section to existing lockfiles, though, unless explicitly requested through bundle lock --add-checksums.
明にbundle lock --add-checksumsを実行しないと自動的にCHECKSUMSを加えてくれないとのことだったので一度だけ手動実行して適用しました。実に良い機能なので使わない手はないですね。
というわけで比較的スッとバージョンを上げることができて良かったです。どんどんやっていきましょう。
*1:コンテナ環境で動かしているのでDockerfileを編集しました
*2:https://ruby-jp.slack.com/archives/CM0DN2H28/p1764746486399459
補足: 履歴テーブル、今回はこう作りました 〜 Delegated Types編 〜
「Ruby on Railsのテーブル設計とトランザクション処理 LT Night」で話した内容のフォローアップです。主に懇親会で ![]() id:kamipo さんから現地でもらった質問を受けての補足となります。
id:kamipo さんから現地でもらった質問を受けての補足となります。
図中のオレンジ枠と緑枠のトランザクションを分けているのはなぜ? ログレコードが保存できてイベントレコードが保存できないことなんてなくない?
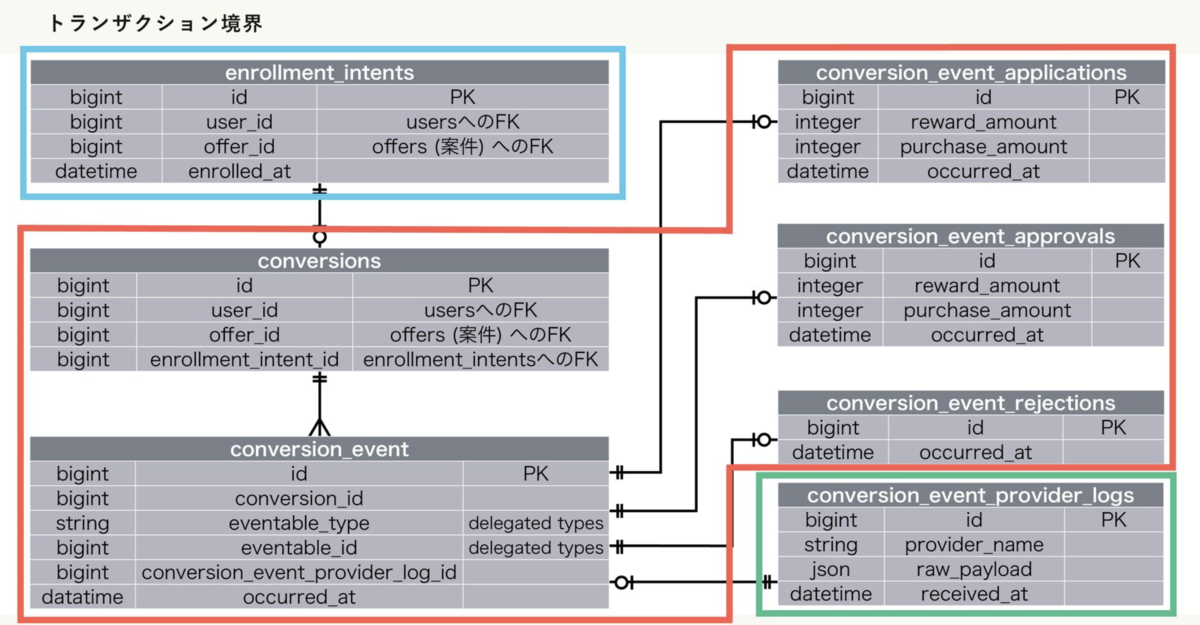
説明がスッポリ抜けていたのですが、ASPからwebhookを受けて諸々の処理をする部分は非同期処理になっているのでそもそもライフサイクルごと分かれていたのでした。つまり、webhookを受けたタイミングでログレコードを記録してからキューイングし、それを非同期的にイベント処理をするので必然的にトランザクションが分かれる。
それはそうとして、イベントを扱う処理中に不慮のクラッシュが発生した時にロギングが巻き込まれると後の調査タスクに影響するので、防御的に作っているというのはそうです。
なぜ非同期処理にしているの?
必ずしもオンラインでやる必要が無いため。キューイングして非同期でやったほうが何かと取り回しが良い (後回しにできるものはしておくと最適化の余地が出てくる)。
enrollment_intentsとconversionsは同じテーブルで扱って良かったのではないか?
enrollment_intentsはユーザーの参加意図を表現していて、conversionsはその参加意図からの実際の参加を表現している。データモデル的には同一に扱えるかもしれないが、行動実態に照らし合わせると別にしたほうが分かりやすい。データを発生させる主体に注目するとenrollment_intentsはユーザーの能動的行動、conversionsはASPからのwebhook受信、とそれぞれ異なるのでライフサイクル的に別物であるという捉え方ができる。
またサービスの特性上、enrollment_intentsのデータ量とconversionsのデータ量は大きく異なる (離脱があるため前者の方が明確に多い) という背景もあり、テーブルを分けているという実情でした。
Delegated TypesじゃなくてSTIで十分だったんじゃないか?
それは本当にそうかもしれない……とはいえ今後の拡張 (提携する事業者が増えるなど) を考えると各ステートのテーブルのcolumnや振舞いが増える可能性が十分にあるので拡張の余地を残すべくDelegated Typesを採用したという背景があります。
スライド中の補足にも書きましたがDelegated Typesだとクエリ数が増え、気を抜くとN+1製造機になるというconsもあるので、そのパフォーマンス面を考慮するとSTIを選択するというのもありかもしれません。
各ステートのテーブルにuser_idとか入れといた方が良さそうじゃない?
それは本当にそう!!!!!!!!!! 絶対に後で必要になるので今入れます。
off-topic: Ruby 4.0.0 preview2とZJITって速い?
まだ評価できるほどのトラフィックを流していませんが、俺は信じています。あとZJITはまだ性能評価の前段階にあるという認識です。俺は信じています。
その他にも、
- RDBMSのカッチリしたテーブル構造とJSON型のcolumnを組み合わせたハイブリッドな構成は今となってはアリなのではないか
- user tableをどのように作るか
- 1つの巨大テーブルとして扱うか、適切にテーブル分割をするか、するとしてどのような基準で分割するか
- 拡張 (例えばALTER時) が辛くなるのであれば分割のサインなのではないか、など
- スライド中にワイプのようにER図を表示すると便利そうだと思って今回のスライドに入れてみた (36ページ目) けれど時間が無くてみなさんにお見せできなかった
などという話題がありました。楽しかったですね。
[追記]
補足の補足をいただきました:
JSON型のcolumnに関してはMySQLであってもexpression indexが貼れるのと、MySQLにできなくてポスグレだと嬉しい点としてスパースなデータに対してテーブル分けたりせずともpartial indexでコンパクトなindexを構築できるという話をしてました。https://t.co/ubFIx7mLDX
— Ryuta Kamizono (@kamipo) 2025年11月29日
DBのcolumn名や、何らかドメインの意味を持つ概念に `type` を名付けない方が良いのではないか
type そのもの、 あるいは _type のようなsuffixを持つ名前を変数や、構造体・クラスのメンバーや、データベースのcolumnなどに付けてしまうことがしばしばあると思うのですが、個人的にはあまりこれはやらない方が良いのではないかと考えています。
理由としては
typeはいくつかのプログラミング言語において予約語になっており、そのセマンティクスにおいて特別な役割を果たすことが多い。- Ruby on RailsにおいてはDelegated Typesという機能において、
_typeというcolumnは特別な意味を持つ (もちろんアプリケーションコード側でDelegated Typesであるという宣言をしなければ副作用は無いのですが)。- その他のフレームワークに似たようなものがあるのかは知りませんが……
というものがあると思っており、そういった概念との衝突を避けるために特別かつ強い理由が無い限りは type という命名は避けようというような気持ちで日々を過ごしています。
代替としては kind や method などが使えそうであると思っておりこれらを採用することが多いです。methodは別の概念との衝突がある場合もありそうですが、そこは文脈に沿って、という感じですかね。どうしても type でしか表現できないものはあると思うのですが (例えば言語処理系を作っていて、本当に「型」を取り扱う必要がある場合など)、そういった場合は頑張りましょう。
かつてRustで `typ` という変数名を乱発していたことに対する戒めを込めています。
Kaigi on Rails 2025でasync gemを使ってSSE機能をRails Appで作るという話をしました #kaigionrails
発表資料はこちらです。以下に資料に入れそびれた・話しそびれたことを以下に記しておきます。
実際のところSSEを導入したのはなぜなのか
今回例示したような「長い時間がかかる処理の進捗報告・完了通知」のような機能はポーリングでも実現可能なものであり、我々のプロダクトでも当初はポーリングを前提として設計がされていたのですが、以下のような理由からSSEを採用するに至って今回の発表に繋がっています:
- ポーリングよりも基本的にはユーザー体験が良くなるはず (ポーリングの場合は変化までに高々インターバル秒かかる可能性がある) *1
- 技術的な挑戦 (おたのしみ)
後者が地味に大事だと考えていて、何か新しい機能やサービスを作ったりする時に「既存のやり方」のみで固定化するのではなく *2、技術的に新しい取り組みをすることによって技術面・組織面での「実力」を高めたいというモチベーションが背景にありました。あと技術的に新しいことをやると純粋に楽しいですからね (楽しいだけではもちろん駄目ですが……)。僕はこれを「おたのしみ」と呼んでいて、新しいものを作る時にはできる限り取り組みたいと考えています。
Active Recordのコネクションをfiber nativeにする方法
スライドに書き忘れていました。
config.active_support.isolation_level = :fiber としてあげると、スライドの49ページ目に書いたようなworkaroundが不要になります *3。
我々も当初この設定を入れようとしていたのですが、既に動いているそこそこの規模のシステムのisolation_levelを変更することに一定のリスクを感じたので見送っていたのでした。とはいえ多くの場合では問題が起こらない気もしますし (もちろん要検証)、少なくとも新たにrails newする時には問題無いと思うので、この設定でトライするのが良いと考えています。
MyModel.with_connection が使える
@ioquatixさんから発表後に教えてもらったのですが、表題のように MyModel.with_connection としてconnectionをborrowできるようになっているとのことです。べんり。
詳細については@ioquatixさんが書いてくださっているgistを参照してください: Show how `with_connection` and `lease_connection` interact. · GitHub
余談ですが、上記gistにあるように config.active_record.permanent_connection_checkout = :disallowed を設定に書いておくのは良さそうに思いました。
Rack 3以降は ActionController::Live を使わなくてもストリーミングレスポンスを返却できる
こちらについても@ioquatixさんから発表後に教えてもらいました。表題の通り、以下のように記述するとSSEでのレスポンスが可能なようです:
上記の例はFalconのものとなっていますがPumaでも問題無く動くとのことでした。これは知らなかった、良いですね。
ご覧の通り、async gemや数々の便利なライブラリ・ツールを作るなどのご活躍をされており、Kaigi on Rails 2025のキーノートスピーカーの@ioquatixさんから色々と教えていただけました。ありがとうございます。
I took a photo with @ioquatix 🥇🥇 #kaigionrails pic.twitter.com/FbGevY1ilL
— moznion (@moznion) 2025年9月26日
Nice talk @moznion !
— Sampo Kuokkanen (@KuokkanenSampo) 2025年9月26日
Love that more people are using @ioquatix ‘s Async. pic.twitter.com/Z1Owkv199Z
テックカンファレンスはこういう交流ができるというのが良いところですね。
*1:ポーリングのほうが仕組みとしてシンプルであるというのは正。そしてSSEであってもコネクション数などの観点でのパフォーマンス優位性はそこまでないので……
*2:もちろん「型」を持っておくのは重要なのですが
*3:https://railsguides.jp/configuring.html#config-active-support-isolation-level
[令和最新]Resemblaをビルドして動かす方法
類似文字列検索ライブラリであるところのResemblaですが、利用に際してはビルド済みのパッケージが配布されていないため自分でビルドする必要があります。
が、Wikiに書かれているインストールドキュメントがCentOS 7のものになっており *1 、現代の環境で動かすにあたってはちょっと工夫が必要……ということで、2025年現代の環境で動作するDockerfileをここに共有します。
ポイントとしては
- mecab-ipadicではなくmecab-ipadic-utf8 を使う (thanks
 id:tomo_ari and
id:tomo_ari and  id:ssig33)
id:ssig33) - icuのバージョンは59.1で固定
- grpcのバージョンはv1.2.5で固定
- Resemblaのビルドに際しても新しめのgccだとエラーが出るのでcstddefをincludeするようにワークアラウンドを入れる *2
という感じでしょうか。このようにしておくと動き、grpcを使ったインターフェイスも動作するところまで持ってゆくことができます。
mecab-unidicをインストールしたい場合、こちらにもちょっとコツが必要なので頑張りましょう:
https://t.co/qJfBQWHL5B が滅亡したことにより、このようなことが発生するhttps://t.co/aaIEIBH5An
— moznion (@moznion) 2025年7月23日
以上です。ご活用ください。